Scrum vs Kanban — что лучше для DS проекта?
Я публиковал результаты воркшопа, где оказалось, что команды, использующие канбан, опережают скрам в уровне зрелости.
Что лучше подходит DS команде — скрам или канбан? В статье мы разберем за и против применения скрама и канбана.

Что такое Скрам в SWE и в чем его сакральный смысл?
Скрам чрезвычайно популярен в разработке ПО (Software Engineering, SWE). Давайте с вами попробуем разобраться почему.
Главная фишка скрама — спринты (итерации). Вот основные принципы:
- У спринта есть цель спринта. Спринт считается успешным, если команда добилась цели спринта.
- Баклог (план) спринта состоит из пользовательских историй. Каждая пользовательская история имеет ценность для пользователя.
- Пользовательские истории начинаются в спринте и доделываются внутри спринта до конца. Если точнее, они должны соответствовать Definition of Done. В зрелых командах это означает, что пользовательская история разработана, протестирована, баги найдены, исправлены и закрыты, продукт задеплоен на stage или prod
Что дает команде такая работа?
- Цель спринта обеспечивает фокус на результате. Грубо говоря, есть чем похвастаться каждый спринт
- Короткий Time to Market. От момента старта разработки до поставки проходит один спринт, в большинстве команд это 2 недели
- Это очень упрощает планирование. Если мы на самом деле фокусируемся на доделывании до конца наших пользовательских историй, то мы не тянем в следующий спринт доделки и баги с прошлых спринтов. Тогда все прозрачно и понятно!
Что отличает Data Science проекты?
Аналогом пользовательской истории в DS является гипотеза. Точно так же, как и пользовательская история, она имеет следующие свойства:
- имеет понятную и измеримую ценность для пользователя или бизнеса,
- может быть доделана до конца,
- выражена языком бизнеса
Большинство DS команд сталкивается со следующей проблемой:
Гипотезу практически невозможно доделать до конца (валидировать) в течении спринта
У гипотезы очень длинный жизненный цикл. Например, в CRISP-DM он выглядит так:
- Business Understanding
- Data Understanding
- Data Preparation
- Modeling
- Evaluation
- Deployment
Сколько времени нужно для валидации гипотезы? Везде по разному, обычно называют цифры от нескольких недель до нескольких месяцев.
Это очень много, по крайней мере в сравнении со скоростью реализации обычной пользовательской истории. В SWE типичное количество пользовательских историй — от 3 до 8 доделанных от начала до конца за спринт.
Второе важное отличие Data Science проектов заключается в следующем. Data Science — discovery process. Каждая гипотеза может с высокой вероятностью провалится и относительно небольшой процент гипотез доезжает до прода и приносит ценность.
SWE — delivery process. С трудом можно представить, чтобы разумно сформулированную пользовательскую историю не удалось доделать или хотя бы показать заказчику.
Чем отличается канбан
В канбан по доске явным образом визуализируется передвижение гипотез по их жизненному циклу.
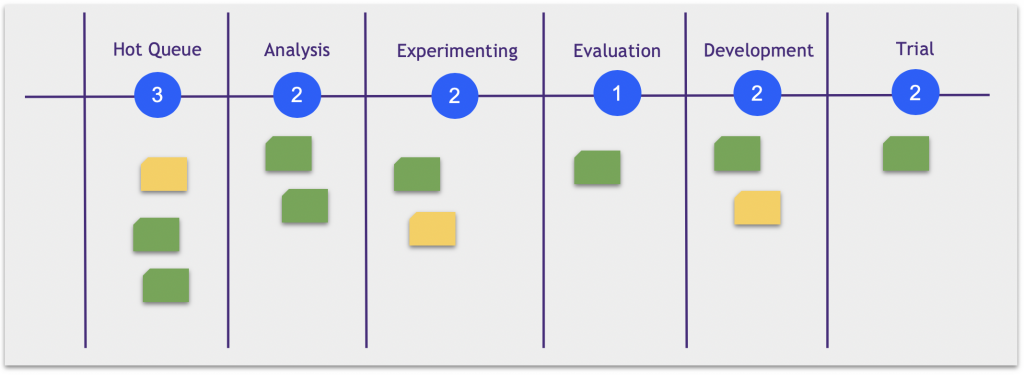
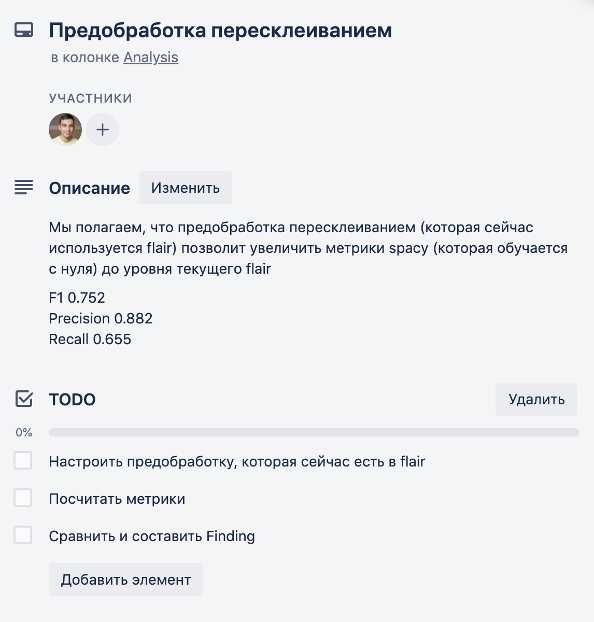
Разбиение на отдельные задачи делается в виде чеклиста прямо под гипотезой. Команды стараются поддерживать его в актуальном состоянии, добавляя новые задачи или удаляя ненужные по мере надобности.
Гипотезы могут отфильтровываться сразу же, не дожидаясь конца спринта.
Как скрам работает в Data Science
Но ведь множество команд работают по скрам! Как они это делают?
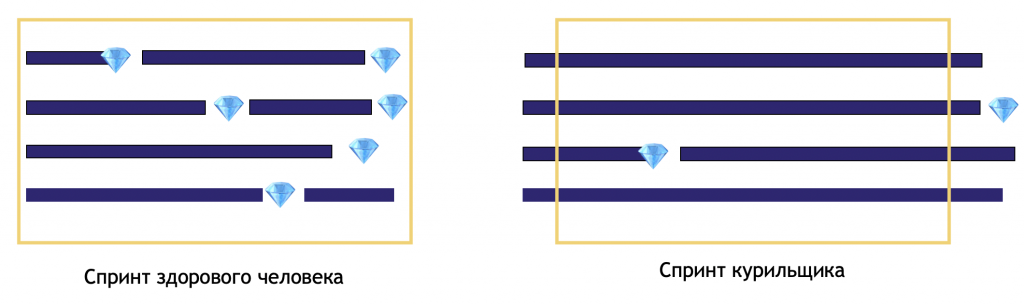
- Никакой разумной цели спринта, как правило, поставить не получается. Даже если вдруг мы формулируем цель, достичь ее к концу спринта практически невозможно
- В конце спринта есть куча недоделанной работы, которая в конце просто переносится на следующий спринт
- Внутри спринта из-за discovery-характера DS проектов может случиться нечто, что полностью уничтожает смысл доделывать спринт до конца
По-сути, спринт превращается в регулярную отбивку времени, просто обозначает частоту встреч команды по планированию.
Как выглядит план спринта? Внутри спринта может оказаться подготовка данных одной гипотезы, моделирование другой, А/Б тестирование третей. При этом из названия задач не понятно, к какой гипотезе она относится, да и сами гипотезы явно не формулируются.
Основная претензия к планированию в стиле скрам — непрозрачность статуса гипотез. Все это усложняет планирование. Приходится контролировать недоделанные работы, переносить их из спринта в спринт, учитывать старые баги.
Эта нагрузка ложится на тимлида. В чертогах его разума находится информация о реальном состоянии дел DS проекта и очень часто нигде больше.

Почему многие команды выбирают скрам?
Мне кажется, тут играет роль некий психологический фактор. Планирование спринта выглядит так: каждый DS набирает себе работы на две недели. Это дает ощущение контроля за происходящим и приятное удовлетворение тем, что все заняты и никто не бездельничает.
Это абсолютно оправдано, если в команде по какой-то причине полно бездельников, которые норовят слиться с работы. Совет тут может быть только один — не надо таких нанимать.
Когда скрам будет более эффективным выбором
Скрам прекрасный подход и его применение в DS разумно, если:
- За спринт вы успеваете провалидировать 3-8 гипотез от начала до конца
- Почти все эти гипотезы попадают в прод
Такое на самом деле возможно. Например, ваша модель давно в проде и вы просто добавляете к ней новые кейсы. При этом у вас очень мало блокирующих факторов. Например, все данные компании доступны в DWH и в прекрасном состоянии.
Фактически, речь идет о команде, поддерживающей уже работающую модель.
Во всех других случаях канбан мне кажется более разумным выбором.
Комментарии (6175)-
Имхо Scrum лучше помогает квотировать ресурсы DS и защищает команду от побочек неидеальности процесса, неопытности участников, вмешательств заинтересованных сторон.
В делах DS (и DA) вижу 2 особенности:
— в работе по проверке гипотезы есть несколько этапов, каждый из которых можно сделать с разной тщательностью и трудозатратами (трейдофф между скоростью и… надёжностью, наглядностью, авторитетностью, воспроизводимостью результата),
— в результате задачи получаются выводы/файндинги, к которым всегда остаются хоть какие-то вопросы/нарекания/сомнения, ответы на которые могут потребовать дополнительного времени.Чтобы бесконфликтно с этим работать, хочется иметь согласованные временнЫе отбивки, сколько человекодней на какую гипотезу и на какой этап задачи мы готовы потратить, прежде чем дадим оценку результату и уточним дальнейшие планы.
В случае с канбаном вопрос «завершена ли задача (проверена ли гипотеза)» становится (полу)политическим, вердикт зависит от того, чей голос громче, кто-то вынесенным вердиктом остаётся недоволен (либо потратим лишнее время на согласование/адаптацию DefinitionOfDone для каждой следующей гипотезы).
В случае со скрамом DS лучше понимает, сколько времени есть на какой этап задачи, а по результатам мы в любом случае закругляем эту задачу и на Демо решаем, достаточно ли полученного по этой гипотезе, или хотим сделать по ней что-то ещё, уже в рамках новой таски, которую взвесим на планировании.
-
Асхат | Опубликовано в 11:05, 19.05.2020
А вы за спринт действительно успеваете валидировать гипотезу? В моем опыте можно успеть сделать какие-то работы по ней, в основном, потому что возня с данными занимает много времени.
То есть DS берет какую-то порученную ему работу по гипотезе до конца спринта. Мы действительно контролируем, но работу, но не гипотезу.
В канбане это также можно делать, указывая сроки следующей проверки гипотезы.
-
Артём | Опубликовано в 12:05, 19.05.2020
>> А вы за спринт действительно успеваете валидировать гипотезу?
Смотря что называть гипотезой и насколько дробить.
Например, что в данных X вообще есть какая-то корреляция с целевым Y (когда ещё нет рабочей модели) — можно,
или что добавление фичи из X может улучшить R2 для Y на 0.05 (когда какая-то модель уже есть) — шансы проверить тоже есть.Если гипотеза большая, её проверку разбиваем на несколько (под)задач (в т.ч. для участников с разной специализацией), одна или несколько из которых в спринт уместятся.
Возможно, вы скажете, что в таком спринте, где гипотеза лежит не целиком, не произойдёт деливери (файндингов),
но всё же показать на Демо (и получить фидбек) обычно есть что, и полезные инсайты по пути тоже всплывают.
Например, удалось интегрировать в систему источник данных, стало видно, что
хотя бы такой пайплайн в инфре заказчика жизнеспособен, данные не слишком упячечные,
но такие-то явления и такие-то ошибки в данных обнаружились,
и само это может нести полезный сигнал для бизнеса «на сдачу»,
чтобы присмотреться-проинтерпретировать, пока мы дальше двигаемся к получению модели.
-
-
-
ммм | Опубликовано в 00:05, 19.05.2020
мммммммм
-
vv | Опубликовано в 00:05, 19.05.2020
vv
-
gg | Опубликовано в 00:05, 19.05.2020
gg
-
qq | Опубликовано в 00:05, 19.05.2020
qq
-
Teddy | Опубликовано в 04:06, 07.06.2020
cialis pills online generic cialis tadalafil free cialis coupon
-
Charlie | Опубликовано в 21:06, 07.06.2020
how to buy genuine cialis online where can i buy generic cialis online cialis price walgreens free sample
of cialis cialis super p force -
Earnestine | Опубликовано в 21:06, 07.06.2020
viagra classification best place to order generic viagra cheap viagra 100mg viagra cialis online canada viagra tablets
buy online in india -
Marisol | Опубликовано в 22:06, 07.06.2020
viagra generika online kaufen ohne kreditkarte viagra online bestellen express cheap viagra soft viagra buy online uk viagra
online kaufen per nachnahme -
Luca | Опубликовано в 05:06, 08.06.2020
online cialis canada erfahrungen mit online apotheken cialis cheapest generic cialis cialis
to buy in uk cialis 5mg online australia
Артём | Опубликовано в 19:05, 18.05.2020